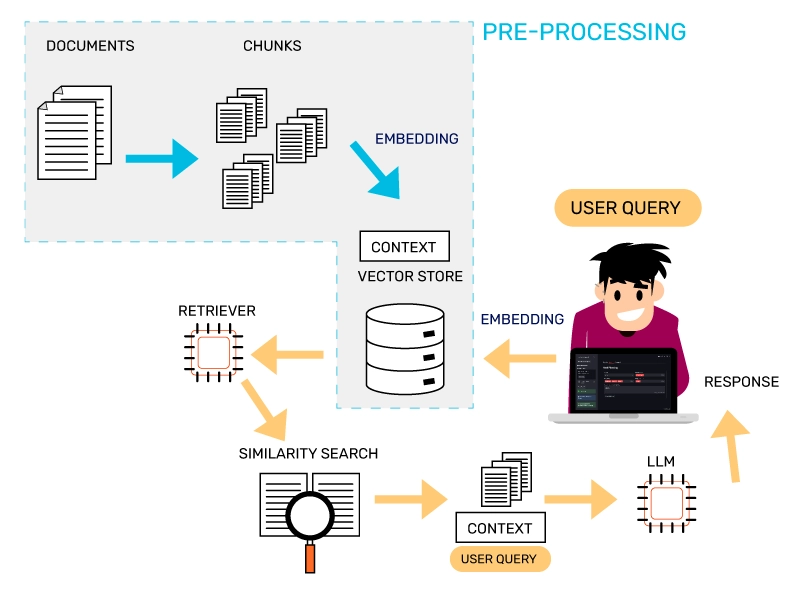
La Retrieval-Augmented Generation (RAG) è un paradigma all'avanguardia nell'intelligenza artificiale che combina la potenza generativa dei modelli linguistici con la precisione del recupero di informazioni da fonti esterne. In parole semplici, invece di affidarsi esclusivamente alla conoscenza "memorizzata" durante l'addestramento, un sistema RAG cerca attivamente informazioni rilevanti in un database o in documenti esterni prima di generare una risposta.
Un sistema RAG è composto da tre componenti fondamentali:
Retrieval (Recupero): Il sistema cerca e recupera informazioni pertinenti da una base di conoscenza o documenti specifici.
Augmentation (Arricchimento): Il modello linguistico viene arricchito con le conoscenze specifiche recuperate.
Generation (Generazione): Una risposta coerente e contestuale viene generata basandosi sia sulla conoscenza generale del modello che sulle informazioni recuperate.
Il RAG risolve alcuni dei problemi più critici dei modelli linguistici tradizionali:
Riduce le "allucinazioni" ancorando le risposte a fonti concrete
Garantisce informazioni aggiornate accedendo a dati recenti
Offre trasparenza e verificabilità con citazioni delle fonti
Permette la personalizzazione senza dover riaddrestrare l'intero modello
Rispetta la privacy mantenendo i dati sensibili nel database dell'utente
Fornisce maggiore controllo agli sviluppatori sulle informazioni disponibili
💡 Vuoi saperne di più sul RAG e come sta rivoluzionando l'interazione con l'AI? Leggi il mio articolo completo sul blog dove approfondisco l'argomento e racconto come questa tecnologia sta trasformando il modo in cui interagiamo con l'intelligenza artificiale.
Introduzione Tecnica al Progetto
Ho sviluppato un'applicazione Streamlit che implementa la tecnologia RAG per creare due strumenti distinti ma complementari:
Document Q&A: Un assistente documentale che permette di caricare file in diversi formati (PDF, DOCX, TXT) e fare domande sul loro contenuto, ricevendo risposte precise e contestuali.
Meal Planner: Un pianificatore di pasti che utilizza ricette in formato JSON per generare piani alimentari personalizzati e liste della spesa ottimizzate.
Questo progetto è nato durante il mio percorso formativo nel bootcamp AI Engineer di Edgemony, ispirato dalle lezioni di Ilyas Chaoua sul RAG. Vediamo in dettaglio l'implementazione tecnica di entrambi i moduli.
Architettura Tecnica del Sistema RAG
L'architettura del sistema RAG implementata segue un flusso di lavoro a quattro fasi principali, ottimizzate per garantire risposte precise, contestuali e verificabili:
1. Indicizzazione e Chunking
Per elaborare documenti e ricette, ho implementato diverse strategie di chunking:
Questo metodo utilizza RecursiveCharacterTextSplitter con una sovrapposizione ottimizzata per mantenere il contesto tra frammenti, un aspetto critico per la comprensione semantica del testo. L'implementazione include separatori specifici per migliorare l'integrità logica dei chunk.
2. Generazione di Embedding e Archiviazione Vettoriale
Gli embedding vengono generati utilizzando il modello di OpenAI e archiviati in un database ChromaDB:
3. Retrieval Ottimizzato e 4. Generazione di Risposte
Il sistema implementa diverse strategie di recupero e generazione, che ho adattato specificamente per ciascun modulo dell'applicazione, come vedremo nelle sezioni dedicate.
Document Q&A: Assistente Documentale Interattivo
Gestione di Documenti Multi-Formato
Per il modulo Document Q&A, ho implementato un sistema di caricamento flessibile che supporta diversi formati:
def load_document(file):
name, extension = os.path.splitext(file)
if extension.lower() == '.pdf':
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file)
elif extension.lower() == '.docx':
from langchain_community.document_loaders import Docx2txtLoader
loader = Docx2txtLoader(file)
elif extension.lower() == '.txt':
from langchain_community.document_loaders import TextLoader
loader = TextLoader(file)
else:
print('Document format is not supported!')
return None
data = loader.load()
return dataCode language:JavaScript(javascript)
Domande e Risposte Contestuali
Il cuore del modulo Document Q&A è la funzione che gestisce le domande dell'utente e genera risposte basate sul contenuto del documento:
def ask_document(vector_store, q, k=3, api_key=None):
# Verifica se la domanda è una richiesta di riassunto
summary_keywords = ["riassumi", "riassunto", "riepilogo", "sintetizza", "sintesi",
"summary", "summarize", "summarise", "overview", "recap"]
lower_q = q.lower()
is_summary_request = any(keyword in lower_q for keyword in summary_keywords)
if is_summary_request:
# Genera un riassunto completoreturn generate_document_summary(vector_store, k=10, api_key=api_key)
else:
# Procedi con la normale domanda e risposta
llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=1, api_key=api_key)
retriever = vector_store.as_retriever(
search_type='similarity', search_kwargs={'k': k})
chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=retriever)
answer = chain.invoke(q)
return answer['result']Code language:PHP(php)
Generazione di Riassunti Intelligenti
Una funzionalità avanzata del sistema è la capacità di generare riassunti completi del documento, utilizzando una strategia migliorata per selezionare le parti più rappresentative:
def generate_document_summary(vector_store, k=10, api_key=None):
llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=0.3, api_key=api_key)
retriever = vector_store.as_retriever(
search_type='mmr', # MMR per una migliore diversità nei risultati
search_kwargs={"k": k, "fetch_k": k*2}
)
# Strategia per ottenere parti rappresentative del documento
docs_beginning = retriever.get_relevant_documents("beginning of document introduction")
docs_middle = retriever.get_relevant_documents("main content central information")
docs_end = retriever.get_relevant_documents("conclusion summary end")
docs_key = retriever.get_relevant_documents("key points important information")
# Combinazione dei documenti evitando duplicati
all_docs = []
seen_content = set()
for doc_list in [docs_beginning, docs_middle, docs_end, docs_key]:
for doc in doc_list:
if doc.page_content not in seen_content:
all_docs.append(doc)
seen_content.add(doc.page_content)
# Prompt specializzato per riassunti
summary_prompt = PromptTemplate(
input_variables=["context"],
template="""You are an expert at summarizing documents.
Please create a comprehensive summary of the following document content.
Focus on the main topics, key points, and overall structure.
Make sure to capture the essence of the document.
Be thorough and informative.
DOCUMENT CONTENT:
{context}
COMPREHENSIVE SUMMARY:"""
)
# Generate summary
chain = LLMChain(llm=llm, prompt=summary_prompt)
result = chain.run(context="\n\n".join([doc.page_content for doc in all_docs]))
return resultCode language:PHP(php)
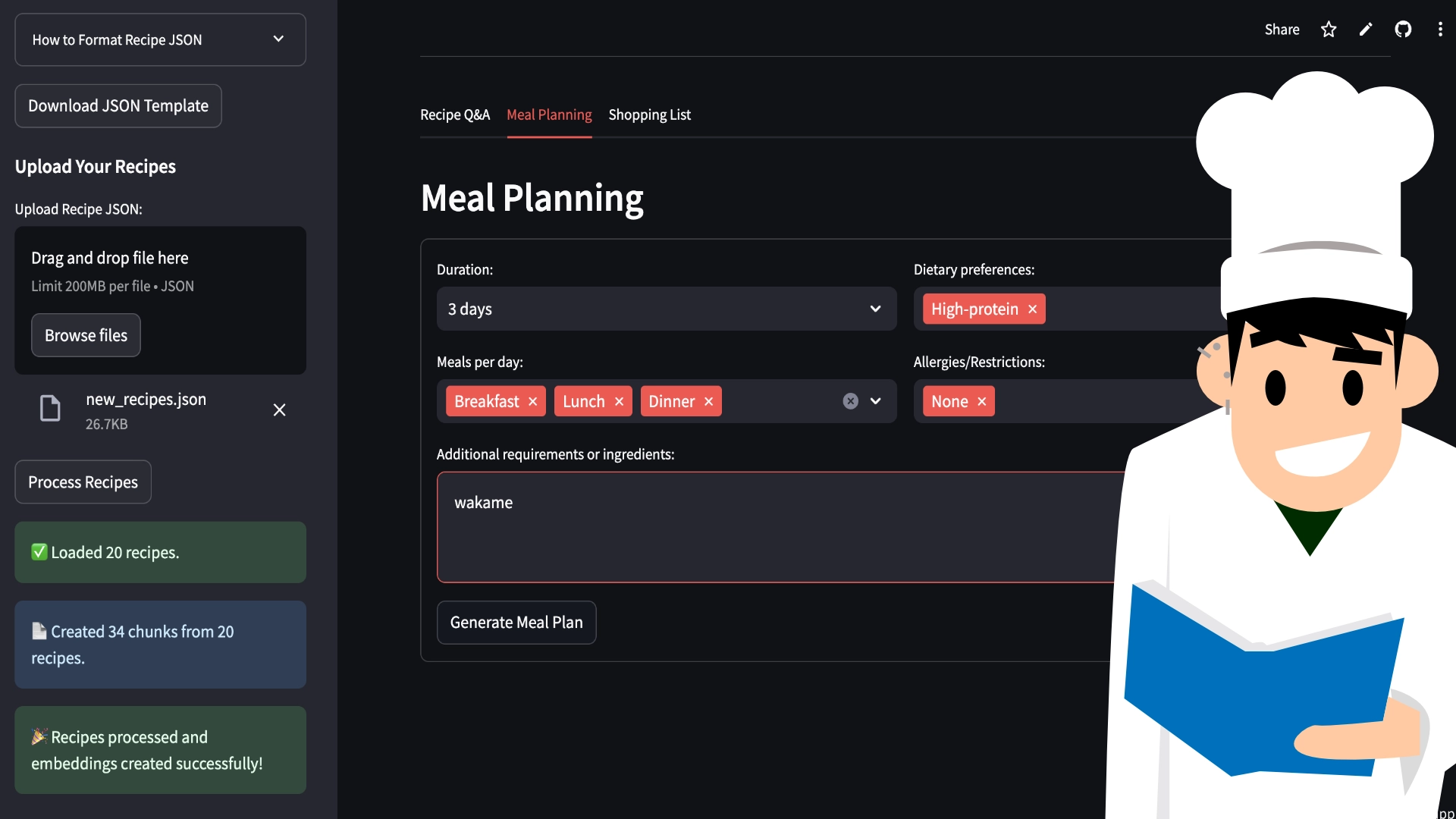
Meal Planner: Pianificatore di Pasti Intelligente
Loader Personalizzato per Ricette
Per il modulo Meal Planner, ho sviluppato un loader personalizzato che struttura i dati delle ricette in JSON:
class RecipeJSONLoader(BaseLoader):
def __init__(self, file_path):
self.file_path = file_path
def load(self):
with open(self.file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
documents = []
for recipe in data["recipes"]:
# Format recipe text with structured sections
recipe_text = f"Title: {recipe['title']}\n"
recipe_text += f"Cuisine: {recipe['cuisine']}\n"
recipe_text += f"Meal Type: {recipe['mealType']}\n"
recipe_text += f"Preparation Time: {recipe['prepTime']}\n"
recipe_text += f"Cooking Time: {recipe['cookTime']}\n"
recipe_text += f"Servings: {recipe['servings']}\n"
recipe_text += f"Dietary Info: {', '.join(recipe['dietaryInfo'])}\n\n"
recipe_text += f"Ingredients:\n"
for ingredient in recipe['ingredients']:
recipe_text += f"- {ingredient}\n"
recipe_text += f"\nInstructions:\n{recipe['instructions']}"
# Recipe-specific metadata
metadata = {
"id": recipe["id"],
"title": recipe["title"],
"cuisine": recipe["cuisine"],
"mealType": recipe["mealType"],
"source": self.file_path
}
doc = Document(page_content=recipe_text, metadata=metadata)
documents.append(doc)
return documents
Q&A Conversazionale per Ricette
Per interagire con le ricette, ho implementato una catena conversazionale con memoria:
Per la pianificazione dei pasti, ho creato una catena specializzata con prompt ottimizzati:
def create_meal_planner_chain(vector_store, api_key=None):
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7, api_key=api_key)
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
# Define specialized prompt for meal planning
meal_planner_template = """
You are a helpful meal planning assistant. Based on the recipe information provided and the user's preferences,
create a meal plan as requested. Use only the recipes mentioned in the context or reasonable variations of them.
Be case-insensitive in your search, meaning treat 'chicken' and 'Chicken' as the same ingredient.
Provide a detailed meal plan with:
- Recipe suggestions for each meal
- Preparation tips from the instructions
- Modifications needed to meet the user's requirements
Format your response in a clear, organized way with headings and bullet points as appropriate.
Context (Recipe Information):
{context}
User Request: {question}
"""
meal_planner_prompt = ChatPromptTemplate.from_template(meal_planner_template)
# Define function to format documents
def format_docs(docs):
return"\n\n".join([doc.page_content for doc in docs])
# Build the meal planner RAG chain
meal_planner_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| meal_planner_prompt
| llm
| StrOutputParser()
)
return meal_planner_chainCode language:PHP(php)
Generazione di Liste della Spesa
Come estensione del pianificatore di pasti, ho implementato un generatore di liste della spesa ottimizzate:
def create_shopping_list_chain(api_key=None):
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0, api_key=api_key)
# Define template for shopping list generation
shopping_list_template = """
You are an assistant specialized in creating shopping lists. Based on the provided meal plan,
create a complete and organized shopping list.
Carefully analyze the following meal plan and identify all necessary ingredients:
{meal_plan}
Generate a shopping list organized by categories (e.g., Proteins, Vegetables, Fruits, Dairy, Condiments, etc.).
Group similar ingredients and indicate the approximate quantity needed to cover the period of the meal plan.
Consider that some recipes may use the same ingredients.
Format your response clearly and neatly, using bullet points to facilitate use during shopping.
"""# Create prompt from template
shopping_list_prompt = ChatPromptTemplate.from_template(shopping_list_template)
# Build the chain for shopping list
shopping_list_chain = (
{"meal_plan": RunnablePassthrough()}
| shopping_list_prompt
| llm
| StrOutputParser()
)
return shopping_list_chainCode language:PHP(php)
Ottimizzazioni Comuni a Entrambi i Moduli
Normalizzazione delle Query
Per migliorare la qualità del retrieval in entrambi i moduli, ho implementato una funzione di normalizzazione delle query.
Interfaccia Utente con Streamlit
L'interfaccia utente è stata implementata con Streamlit, organizzata in moduli distinti con una navigazione intuitiva.
Conclusione
Questo progetto dimostra l'implementazione pratica di un sistema RAG completo attraverso due applicazioni distinte ma complementari. Il Document Q&A offre un assistente documentale interattivo che permette di estrarre informazioni precise da documenti complessi, mentre il Meal Planner utilizza la stessa tecnologia per creare piani alimentari personalizzati basati su una collezione di ricette.
L'architettura modulare dell'applicazione permette estensioni future, come l'integrazione di agenti AI con architetture di memoria multipla, rendendo il sistema adattabile a diversi casi d'uso.
Il progetto esemplifica come le tecniche avanzate di intelligenza artificiale possano essere applicate a problemi quotidiani, migliorando significativamente l'esperienza utente nell'interazione con documenti complessi e nella pianificazione dei pasti.
Il codice completo è disponibile su GitHub, e l'applicazione è accessibile attraverso Streamlit, dimostrando la fattibilità di creare soluzioni RAG pratiche e accessibili con le tecnologie attuali.
• Sviluppo del sito web di Chanteclair utilizzando WordPress, sfruttando Oxygen Builder per un design personalizzato e flessibile, e Advanced Custom Fields (ACF) per la gestione dinamica del contenuto, migliorando sia l’aspetto che l’usabilità. • Questo progetto è stato realizzato mentre ricoprivo il ruolo di Head of Web Development presso DigitalMakers. Tecnologie utilizzate: WordPress, Oxygen […]
Ogni tanto capita un progetto che ti cambia la prospettiva. Per me, questo è stato uno di quelli. Durante il corso Build AI Agents with AWS di Zero To Mastery, ho avuto la sensazione di aver sbloccato un nuovo livello: Mi ha fatto scoprire un mondo completamente nuovo: quello dell’orchestrazione multi-agente in cloud, dove ogni […]