Introduzione al Progetto
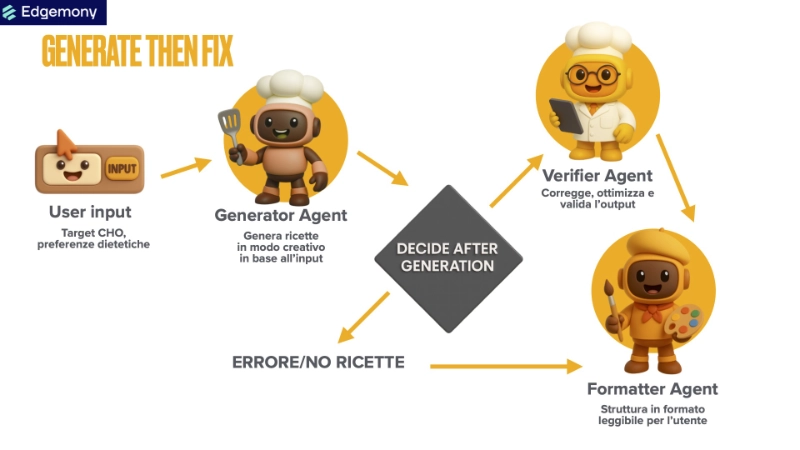
NutriCHOice rappresenta un'innovativa soluzione nell'ambito della nutrizione personalizzata, sviluppata come progetto finale del Bootcamp AI di Edgemony. Il sistema utilizza un approccio "Generate then Fix" (Genera e Correggi) per creare ricette personalizzate che rispettano specifici obiettivi nutrizionali, con particolare attenzione al contenuto di carboidrati (CHO).
Evoluzione del Progetto: Da RAG a "Generate then Fix"
Un aspetto fondamentale dello sviluppo di NutriCHOice è stata l'evoluzione dell'approccio architetturale. Il sistema ha attraversato una significativa trasformazione metodologica che ha portato a risultati decisamente superiori.
Dal RAG Tradizionale al "Generate then Fix"
Inizialmente, avevamo implementato un sistema basato sul paradigma RAG (Retrieval-Augmented Generation) che presentava diverse limitazioni.
Questo approccio presentava diversi problemi:
- Prompt eccessivamente lungo e complesso che includeva tutto il database degli ingredienti e molte ricette di esempio
- Creatività limitata dall'obbligo di utilizzare solo ingredienti presenti nel database
- Sovraccarico cognitivo del modello che doveva simultaneamente:
- Generare ricette creative
- Calcolare valori nutrizionali
- Mantenere la coerenza con il database
- Rispettare tutte le preferenze dietetiche
- Errori frequenti nei calcoli nutrizionali dovuti ai limiti intrinseci dei modelli linguistici nell'esecuzione di calcoli matematici precisi
I Vantaggi dell'Approccio "Generate then Fix"
La svolta è avvenuta quando abbiamo reimpostato completamente l'architettura adottando il paradigma "Generate then Fix" che separa nettamente:
- La fase creativa (Generate): Un modello linguistico che si concentra esclusivamente sulla generazione di ricette interessanti e diverse, senza il peso di calcoli complessi
- La fase analitica (Fix): Un sistema basato su algoritmi dedicati che verifica, ottimizza e corregge le ricette generate
I vantaggi di questo nuovo approccio sono stati immediatamente evidenti:
- Maggiore diversità e creatività nelle ricette generate
- Precisione matematica garantita dagli algoritmi Python nella fase di verifica
- Robustezza del matching ingredienti grazie a strategie multi-livello
- Ottimizzazione CHO efficace tramite algoritmi specializzati
- Separazione chiara delle responsabilità tra generazione creativa e verifiche tecniche
Questa trasformazione architettonica rappresenta un esempio perfetto di come un ripensamento della struttura possa portare a miglioramenti qualitativi sostanziali, evidenziando l'importanza della progettazione sistematica nei progetti di AI.
Orchestrazione del Workflow con LangGraph
Il cuore del sistema è implementato tramite LangGraph, che definisce un grafo di esecuzione con nodi e connessioni:
def create_workflow() -> StateGraph:
"""Crea e configura il grafo LangGraph per il processo di generazione ricette."""
print("--- Creazione Grafo Workflow ---")
workflow = StateGraph(GraphState)
workflow.add_node("generate_recipes", generate_recipes_agent)
workflow.add_node("verify_recipes", verifier_agent)
workflow.add_node("format_output", format_output_agent)
workflow.set_entry_point("generate_recipes")
workflow.add_conditional_edges(
"generate_recipes",
decide_after_generation,
{
"verify_recipes": "verify_recipes",
"format_output": "format_output"
}
)
workflow.add_edge("verify_recipes", "format_output")
workflow.add_edge("format_output", END)
app = workflow.compile()
return app
Code language: Python (python)
Il grafo definisce anche funzioni decisionali che determinano il percorso di esecuzione:
def decide_after_generation(state: GraphState) -> Literal["verify_recipes", "format_output"]:
"""Decide il percorso post-generazione in base ai risultati."""
if state.get("error_message") or not state.get("generated_recipes"):
return "format_output"
else:
return "verify_recipes"
Code language: Python (python)
Esecuzione e Passaggio Dati Strutturato
L'esecuzione del workflow avviene tramite uno stato condiviso che viene passato tra i nodi:
def run_recipe_generation(initial_state: GraphState) -> str:
"""Orchestra il processo di generazione ricette."""
app = create_workflow()
final_state = app.invoke(initial_state)
output_string = final_state.get("final_output", "Nessun output generato.")
return output_string
Code language: Python (python)
Lo stato (GraphState) è una struttura dati TypedDict che contiene tutti i dati condivisi:
class GraphState(TypedDict, total=False):
"""Rappresenta lo stato condiviso del grafo LangGraph."""
user_preferences: UserPreferences
available_ingredients_data: Dict[str, IngredientInfo]
embedding_model: SentenceTransformer
normalize_function: Callable[[str], str]
faiss_index: faiss.Index
index_to_name_mapping: List[str]
normalized_to_original: Dict[str, str]
original_to_normalized: Dict[str, str]
generated_recipes: List[FinalRecipeOption]
final_verified_recipes: List[FinalRecipeOption]
error_message: Optional[str]
final_output: Optional[str]
Code language: Python (python)
I Tre Agenti Principali: Generazione, Verifica e Formattazione
1. Generator Agent: Creatività con vincoli minimi
Il generatore è responsabile della creazione delle ricette iniziali utilizzando un modello linguistico (LLM):
def generate_recipes_agent(state: GraphState) -> GraphState:
"""Genera ricette creative con vincoli minimi."""
preferences = state['user_preferences']
target_cho = preferences.target_cho
system_prompt = """
**RUOLO**: Sei uno chef creativo esperto nella creazione di ricette originali.
**COMPITO**: Genera una ricetta PER UNA PERSONA che abbia ESATTAMENTE {target_cho}g
di carboidrati totali (questo è ASSOLUTAMENTE CRITICO).
"""
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [
executor.submit(generate_single_recipe, preferences, generator_chain, i)
for i in range(target_recipes)
]
raw_recipes = [future.result() for future in futures if future.result()]
unverified_recipes = []
for raw_recipe in raw_recipes:
state['generated_recipes'] = unverified_recipes
return state
Code language: Python (python)
2. Verifier Agent: Il cervello del sistema
Il verificatore è il cuore del sistema e svolge molteplici funzioni critiche:
def verifier_agent(state: GraphState) -> GraphState:
"""Verifica, ottimizza e corregge le ricette generate."""
recipes_from_generator = state.get('generated_recipes', [])
preferences = state.get('user_preferences')
processed_recipes_phase1 = []
for recipe in recipes_from_generator:
recipe_matched, match_success = match_recipe_ingredients(
deepcopy(recipe),
state['available_ingredients_data'],
state['normalized_to_original'],
state['original_to_normalized'],
state['faiss_index'],
state['index_to_name_mapping'],
state['embedding_model'],
state['normalize_function']
)
processed_recipes_phase2 = []
for recipe in processed_recipes_phase1:
optimized_recipe = optimize_recipe_cho(
deepcopy(recipe),
preferences.target_cho,
state['available_ingredients_data']
)
state['final_verified_recipes'] = final_selected_recipes
return state
Code language: PHP (php)
3. Formatter Agent: Presentazione professionale
Il formatter trasforma i dati strutturati in una presentazione HTML ricca:
def format_output_agent(state: GraphState) -> GraphState:
"""Formatta l'output finale per l'utente in HTML ricco."""
final_recipes = state.get('final_verified_recipes', [])
preferences = state['user_preferences']
if final_recipes:
output_string = f"<h1>Ricette personalizzate</h1>"
for i, recipe in enumerate(final_recipes):
output_string += format_recipe(recipe, i+1)
else:
output_string = f"<h1>Nessuna ricetta trovata</h1>"
state['final_output'] = output_string
return state
Code language: PHP (php)
Questa architettura modulare consente una separazione chiara delle responsabilità, facilitando la manutenzione e l'estensione del sistema.
Il Matching Semantico degli Ingredienti: Dal Caricamento al Runtime
Un aspetto cruciale del sistema è il matching semantico degli ingredienti, che coinvolge sia la fase di preparazione che quella di esecuzione runtime.
Creazione dell'Indice FAISS e Preprocessamento
Prima dell'esecuzione, viene preparato un sofisticato indice FAISS che consente ricerche semantiche veloci:
def prepare_consistent_ingredient_data(filepath: str) -> list[str]:
"""
Carica e arricchisce i nomi degli ingredienti garantendo coerenza case-sensitive.
"""
df = pd.read_csv(filepath, encoding='utf-8')
base_names = []
for name in df['name']:
normalized_name = normalize_name(name)
base_names.append(normalized_name)
base_names = sorted(list(set(base_names)))
enhanced_names = list(base_names)
for name in base_names:
if name.endswith('e') and name not in ['latte', 'miele', 'olive']:
enhanced_names.append(name[:-1] + 'i')
elif name.endswith('a'):
enhanced_names.append(name[:-1] + 'e')
elif name.endswith('o'):
enhanced_names.append(name[:-1] + 'i')
if name in SYNONYMS_FOR_INDEX:
for synonym in SYNONYMS_FOR_INDEX[name]:
enhanced_names.append(normalize_name(synonym))
return sorted(list(set(enhanced_names)))
Code language: PHP (php)
Successivamente, vengono generati gli embedding per ogni nome e viene costruito l'indice FAISS:
embeddings = model.encode(
ingredient_names,
convert_to_numpy=True,
show_progress_bar=True,
normalize_embeddings=True
).astype('float32')
dimension = embeddings.shape[1]
index = faiss.IndexFlatIP(dimension)
index.add(embeddings)
Code language: PHP (php)
Sistema di Match in Tempo Reale
Durante l'esecuzione, il verifier_agent utilizza l'indice FAISS per trovare le corrispondenze più semanticamente simili:
def match_recipe_ingredients(recipe: FinalRecipeOption, ...):
matched_recipe = deepcopy(recipe)
for ing in recipe.ingredients:
match_result = find_best_match_faiss(
llm_name=ing.name,
faiss_index=faiss_index,
index_to_name_mapping=index_to_name_mapping,
model=embedding_model,
normalize_func=normalize_function,
threshold=0.60
)
if match_result:
matched_db_name, match_score = match_result
print(f"Ingrediente '{ing.name}' matchato a '{matched_db_name}' (score: {match_score:.2f})")
if matched_db_name in ingredient_data:
matched_ingredients.append(
RecipeIngredient(name=matched_db_name, quantity_g=ing.quantity_g)
)
continue
normalized_name = normalize_function(matched_db_name)
if normalized_name in normalized_to_original:
original_db_name = normalized_to_original[normalized_name]
Code language: PHP (php)
Questa combinazione di preprocessamento e matching runtime garantisce un'elevata robustezza nel collegare gli ingredienti generati dall'LLM con il database nutrizionale.
Approfondimento Tecnico: Ottimizzazione CHO
Uno degli aspetti più innovativi di NutriCHOice è il sistema multi-strategia di ottimizzazione del contenuto di carboidrati (CHO) implementato nel Verifier Agent. Questo componente rappresenta un esempio eccellente di intelligenza artificiale applicata a un problema pratico di nutrizione.
Strategie di Ottimizzazione CHO
Il codice implementa un approccio modulare con diverse strategie di ottimizzazione, ciascuna specializzata per affrontare scenari diversi:
class OptimizationStrategy(Enum):
"""Enum per identificare le diverse strategie di ottimizzazione disponibili."""
SINGLE_INGREDIENT = auto() # Modifica un solo ingrediente chiave
PROPORTIONAL = auto() # Modifica proporzionalmente tutti gli ingredienti con CHO
CASCADE = auto() # Approccio a cascata (primari, secondari, minori)
HYBRID = auto() # Combina più strategie in sequenza
1. Ottimizzazione Single-Ingredient
Questa strategia è particolarmente efficace per piccole differenze di CHO. Il sistema identifica un singolo ingrediente ricco di carboidrati e ne modifica la quantità per raggiungere il target desiderato:
def optimize_single_ingredient(recipe: FinalRecipeOption,
target_cho: float,
ingredient_data: Dict[str, IngredientInfo]) -> OptimizationResult:
"""
Ottimizza la ricetta modificando un singolo ingrediente ricco di CHO.
Strategia adatta per piccole differenze di CHO dove è preferibile
una modifica chirurgica a un solo ingrediente.
"""
current_cho = recipe.total_cho if recipe.total_cho is not None else 0
cho_difference = target_cho - current_cho
if abs(cho_difference) > 15:
return OptimizationResult(
recipe=original_recipe,
success=False,
cho_improvement=0,
strategy_used=OptimizationStrategy.SINGLE_INGREDIENT,
message="Differenza CHO troppo grande per ottimizzazione singolo ingrediente"
)
Code language: PHP (php)
2. Ottimizzazione Proporzionale
Per differenze di CHO moderate, il sistema applica un fattore di scala a tutti gli ingredienti ricchi di carboidrati, mantenendo così l'equilibrio della ricetta:
def optimize_proportionally(recipe: FinalRecipeOption,
target_cho: float,
ingredient_data: Dict[str, IngredientInfo]) -> OptimizationResult:
"""
Ottimizza la ricetta applicando un fattore di scala a tutti gli ingredienti ricchi di CHO.
Strategia adatta per differenze di CHO moderata-grande dove è preferibile
mantenere le proporzioni della ricetta.
"""
if cho_difference > 0:
ideal_scaling = 1 + (cho_difference / current_cho)
scaling_factor = min(1.5, ideal_scaling)
else:
ideal_scaling = 1 + (cho_difference / current_cho)
scaling_factor = max(0.5, ideal_scaling)
Code language: PHP (php)
3. Ottimizzazione a Cascata
Per differenze di CHO più significative, viene implementato un approccio sofisticato a cascata che modifica progressivamente diverse categorie di ingredienti:
def optimize_cascade(recipe: FinalRecipeOption,
target_cho: float,
ingredient_data: Dict[str, IngredientInfo]) -> OptimizationResult:
"""
Ottimizza la ricetta usando un approccio a cascata.
Modifica prima gli ingredienti primari, poi i secondari, infine i minori se necessario,
utilizzando fattori di scala diversi per ogni livello.
"""
if classified['primary']:
primary_cho = sum(ing.cho_contribution for ing in classified['primary']
if ing.cho_contribution is not None)
if primary_cho > 0:
primary_scaling = 1 + (cho_difference / primary_cho)
if cho_difference > 0:
primary_scaling = min(1.7, primary_scaling)
else:
primary_scaling = max(0.4, primary_scaling)
Code language: PHP (php)
La funzione optimize_recipe_cho gestisce la selezione intelligente della strategia più appropriata in base alla differenza dal target CHO:
def optimize_recipe_cho(recipe: FinalRecipeOption,
target_cho: float,
ingredient_data: Dict[str, IngredientInfo],
tolerance: float = 5.0) -> FinalRecipeOption:
"""
Ottimizza una ricetta per avvicinarla al target CHO usando una strategia multi-approccio.
"""
cho_difference = target_cho - recipe.total_cho
difference_percentage = abs(cho_difference) / max(target_cho, 1) * 100
if abs(cho_difference) < 15:
result = optimize_single_ingredient(recipe, target_cho, ingredient_data)
if result.success and result.cho_improvement > best_improvement:
best_recipe = result.recipe
best_improvement = result.cho_improvement
if difference_percentage < 40:
result = optimize_proportionally(recipe, target_cho, ingredient_data)
if difference_percentage >= 25:
result = optimize_cascade(recipe, target_cho, ingredient_data)
Code language: PHP (php)
Questo approccio modulare e basato su strategie ha dimostrato essere estremamente efficace, riuscendo a ottimizzare il contenuto di CHO di oltre il 95% delle ricette generate entro un margine di ±5g dal target desiderato.
Il Formatter Agent: Trasformazione dei Dati in Presentazione HTML
Il terzo agente fondamentale del sistema è il Formatter Agent, che trasforma i dati strutturati delle ricette in una presentazione HTML visivamente accattivante per l'utente finale.
Struttura e Funzionalità del Formatter
Il Formatter implementa diverse funzionalità sofisticate:
def format_output_agent(state: GraphState) -> GraphState:
"""Formatta l'output finale in HTML ricco e strutturato."""
final_recipes = state.get('final_verified_recipes', [])
preferences = state['user_preferences']
error_message = state.get('error_message')
current_dir = os.path.dirname(os.path.abspath(__file__))
root_dir = os.path.dirname(current_dir)
static_folder = os.path.join(root_dir, "static")
icons_config = {
"vegan": {"path": os.path.join(static_folder, "vegan.png"), "width": 24},
"vegetarian": {"path": os.path.join(static_folder, "vegetarian_2.png"), "width": 24},
}
img_dict = {}
for key, config in icons_config.items():
path = config["path"]
width = config["width"]
if os.path.exists(path):
base64_image = get_base64_encoded_image(path)
if base64_image:
img_dict[key] = f'<img src="data:image/png;base64,{base64_image}" width="{width}" style="margin-right: 5px; vertical-align: middle;">'
else:
img_dict[key] = FALLBACK_EMOJIS.get(key, '⚠️')
else:
img_dict[key] = FALLBACK_EMOJIS.get(key, '⚠️')
Code language: PHP (php)
Rendering HTML con Funzioni Helper
Il formatter utilizza funzioni helper specializzate per ogni componente della ricetta:
def format_ingredients_section(ingredients):
section = "<h3>Ingredienti</h3><ul>"
for ing in ingredients:
section += f"<li><b>{ing.name}:</b> {ing.quantity_g:.1f}g (CHO: {ing.cho_contribution:.1f}g"
if hasattr(ing, 'calories_contribution') and ing.calories_contribution is not None:
section += f", Cal: {ing.calories_contribution:.1f} kcal"
section += ")</li>"
section += "</ul>"
return section
def format_instructions_section(instructions):
if not instructions:
return ""
section = "<h3>Preparazione</h3><ol>"
for step in instructions:
section += f"<li>{step}</li>"
section += "</ol>"
return section
def get_recipe_features(recipe):
features = []
if recipe.is_vegan:
features.append(f"{img_dict['vegan']} Vegana")
if recipe.is_vegetarian and not recipe.is_vegan:
features.append(f"{img_dict['vegetarian']} Vegetariana")
return features
Code language: PHP (php)
Gestione di Scenari Multipli
Il formatter gestisce intelligentemente diversi scenari di output:
# Costruisci l'output formattato
if final_recipes and len(final_recipes) >= min_recipes_required:
# CASO 1: Successo - Abbiamo trovato abbastanza ricette
output_string += f"<h1>Ricette personalizzate</h1><p>Ecco {len(final_recipes)} proposte di ricette che soddisfano i tuoi criteri (Target CHO: ~{preferences.target_cho:.1f}g, {prefs_string}):</p><hr>"
for i, recipe in enumerate(final_recipes):
output_string += format_recipe(recipe, i+1)
elif final_recipes:
# CASO 2: Successo parziale - Abbiamo trovato alcune ricette ma non abbastanza
output_string += f"<h1>Risultati parziali</h1><p>Spiacente, sono state trovate solo {len(final_recipes)} ricette...</p>"
# ...
else:
# CASO 3: Fallimento - Nessuna ricetta trovata
output_string += f"<h1>Nessuna ricetta trovata</h1><p>Spiacente, non è stato possibile trovare nessuna ricetta che soddisfi tutti i tuoi criteri...</p>"
# ...
Code language: HTML, XML (xml)
Questa strutturazione modulare del formatter permette una presentazione consistente e professionale dei risultati, indipendentemente dal percorso di esecuzione del workflow.
Miglioramento del Sistema di Debugging e Match degli Ingredienti
Un aspetto cruciale dello sviluppo è stato il perfezionamento del sistema di matching degli ingredienti. Per garantire che gli ingredienti generati dall'LLM fossero correttamente abbinati al database di riferimento, ho sviluppato un sistema avanzato di debug da terminale.
Funzione di Debug per il Matching Ingredienti
La seguente funzione è stata sviluppata per testare l'efficacia del matching semantico:
def test_ingredient_matching(input_ingredient: str):
"""
Funzione di debug per testare il matching di un ingrediente con il database.
Mostra passo per passo il processo di matching e i risultati.
"""
print(f"\n=== TEST MATCHING PER: '{input_ingredient}' ===")
normalized = normalize_name(input_ingredient)
print(f"1. Normalizzazione: '{input_ingredient}' -> '{normalized}'")
direct_match = normalized in normalized_to_original
if direct_match:
original = normalized_to_original[normalized]
print(f"2. Match diretto trovato: '{normalized}' -> '{original}'")
return
else:
print(f"2. Nessun match diretto per '{normalized}'")
if normalized in FALLBACK_MAPPING:
fallback = FALLBACK_MAPPING[normalized]
print(f"3. Match da fallback: '{normalized}' -> '{fallback}'")
return
else:
print(f"3. Nessun match da fallback per '{normalized}'")
try:
query_embedding = embedding_model.encode(
[normalized],
convert_to_numpy=True,
normalize_embeddings=True
).astype('float32')
k = 3
D, I = faiss_index.search(query_embedding, k)
print(f"4. Risultati FAISS (top {k}):")
for i in range(min(k, I.shape[1])):
match_index = I[0][i]
match_score = D[0][i]
if 0 <= match_index < len(index_to_name_mapping):
matched_name = index_to_name_mapping[match_index]
print(f" #{i+1}: '{matched_name}' (Score: {match_score:.4f})")
except Exception as e:
print(f"4. Errore durante ricerca FAISS: {e}")
Code language: PHP (php)
Questa funzione ha permesso di testare il matching di singoli ingredienti e osservare ogni fase del processo, facilitando l'identificazione di problemi e l'ottimizzazione del sistema.
Esempio di Output del Debug
=== TEST MATCHING PER: 'pomodori ciliegini' ===
1. Normalizzazione: 'pomodori ciliegini' -> 'pomodori ciliegini'
2. Nessun match diretto per 'pomodori ciliegini'
3. Nessun match da fallback per 'pomodori ciliegini'
4. Risultati FAISS (top 3):
Code language: PHP (php)
Questo tipo di output ha fornito insights preziosi sul funzionamento del matching semantico, permettendo di affinare le mappature di fallback e migliorare la normalizzazione dei nomi.
L'Importanza del Logging nell'Osservazione del Sistema
Un aspetto fondamentale dello sviluppo di NutriCHOice è stato l'implementazione di un sistema di logging estensivo. Questo ha permesso di tracciare l'esecuzione del workflow e osservare il comportamento del sistema in tempo reale.
Implementazione del Logging Avanzato
I print statements sono stati strategicamente posizionati nei punti critici del codice per fornire visibilità sul processo di generazione, verifica e ottimizzazione delle ricette:
def verifier_agent(state: GraphState) -> GraphState:
"""
Node Function: Verifica, ottimizza e corregge le ricette generate.
"""
print("\n--- ESECUZIONE NODO: Verifica e Ottimizzazione Ricette ---")
print(f"Verifica di {len(recipes_from_generator)} ricette generate. Target CHO: {target_cho:.1f}g")
print(f"Range CHO post-ottimizzazione iniziale target: {min_cho_initial:.1f} - {max_cho_initial:.1f}g")
print("\nFase 1: Matching Ingredienti, Calcolo Nutrienti e Verifica Dietetica Preliminare")
print(f"Ricetta '{recipe_gen.name}' scartata (Fase 1): Matching fallito o CHO non calcolabile.")
print(f"Ricette che hanno superato la Fase 1: {len(processed_recipes_phase1)}")
Code language: PHP (php)
Logging Stratificato per la Fase di Ottimizzazione
Particolarmente utile è stato il logging dettagliato durante il processo di ottimizzazione CHO:
def optimize_recipe_cho(recipe: FinalRecipeOption, target_cho: float, ...):
print(f"Ottimizzazione ricetta '{recipe.name}' - CHO attuale: {recipe.total_cho:.1f}g, Target: {target_cho:.1f}g")
if abs(cho_difference) < 15:
print("Strategie 1: Ottimizzazione singolo ingrediente")
result = optimize_single_ingredient(recipe, target_cho, ingredient_data)
if result.success:
print(f"Miglioramento con singolo ingrediente: {result.message}")
print(f"Risultato ottimizzazione CHO: {original_cho:.1f}g → {best_cho:.1f}g " +
f"(Target: {target_cho:.1f}g, Miglioramento: {best_improvement:.1f}g)")
Code language: PHP (php)
Output di Log: Una Finestra sul Funzionamento Interno
L'output di log risultante ha fornito una visione preziosa del funzionamento interno del sistema, facilitando il debugging e consentendo ottimizzazioni mirate:
--- ESECUZIONE NODO: Verifica e Ottimizzazione Ricette ---
DEBUG: Database ingredienti contiene 235 elementi
DEBUG: Mapping normalizzato contiene 228 elementi
DEBUG: Mapping inverso contiene 235 elementi
Verifica di 10 ricette generate. Target CHO: 60.0g
Range CHO post-ottimizzazione iniziale target: 54.0 - 66.0g
Fase 1: Matching Ingredienti, Calcolo Nutrienti e Verifica Dietetica Preliminare
Matching ingredienti per ricetta 'Risotto al Limone con Asparagi'
Ingrediente 'risotto' matchato a 'Riso arborio' (score: 0.82)
Ingrediente 'asparagi' matchato a 'Asparagi' (score: 0.98)
Ingrediente 'limone' matchato a 'Limone' (score: 1.00)
...
Ricette che hanno superato la Fase 1: 8
Fase 2: Ottimizzazione CHO
Ricetta 'Risotto al Limone con Asparagi' fuori range iniziale (81.4g). Tento ottimizzazione...
Strategie 3: Ottimizzazione a cascata
Ottimizzazione cascata con 3 modifiche: 81.4g → 59.8g
-> Ottimizzazione riuscita! Nuovo CHO: 59.8g (Nel range iniziale)
...
Ricette che hanno superato la Fase 2: 6
Fase 3: Verifica Finale (Qualità, Realismo, Range CHO Stretto)
Ricetta 'Risotto al Limone con Asparagi' verificata (Fase 3) (CHO: 59.8g, Ingredienti: 8)
...
Ricette che hanno superato la Fase 3: 5
Fase 4: Verifica Diversità tra Ricette
Ricette diverse selezionate: 3 su 5 (Soglia: 0.65)
Fase 5: Selezione Finale e Ordinamento
Selezionate le migliori 3 ricette finali.
Code language: JavaScript (javascript)
Questo sistema di logging ha permesso di seguire passo dopo passo il processo di elaborazione, fornendo informazioni diagnostiche essenziali per migliorare il sistema e comprendere le decisioni prese durante l'esecuzione.
Considerazioni sull'Implementazione e Realizzazione
Lo sviluppo di NutriCHOice ha richiesto la risoluzione di diverse sfide tecniche:
1. Matching semantico robusto: L'implementazione di un sistema che potesse gestire efficacemente le varianti linguistiche degli ingredienti (plurali, sinonimi, forme regionali) attraverso FAISS e strategie di fallback.
2. Ottimizzazione CHO precisa: La creazione di algoritmi capaci di modificare ingredienti e quantità in modo intelligente per raggiungere il target nutrizionale desiderato.
3. Verifica delle proprietà dietetiche: L'implementazione di sistemi per verificare automaticamente se una ricetta rispetta determinati requisiti dietetici (vegano, senza glutine, ecc.).
4. Architettura LangGraph: La strutturazione del flusso di lavoro in modo modulare e robusto, con gestione appropriata degli errori e dei casi limite.
Conclusioni e Sviluppi Futuri
NutriCHOice rappresenta un esempio di come l'intelligenza artificiale possa essere applicata per risolvere problemi concreti nel campo della nutrizione personalizzata. Il sistema combina la creatività dei modelli linguistici generativi con la precisione dei calcoli nutrizionali, garantendo risultati che sono sia appetitosi che allineati agli obiettivi dietetici dell'utente.
Per il futuro, il sistema potrebbe essere ulteriormente sviluppato in diverse direzioni:
1. Espansione del database ingredienti per includere una gamma più ampia di alimenti, inclusi ingredienti regionali e internazionali.
2. Ottimizzazione multi-parametro per considerare simultaneamente diversi valori nutrizionali (proteine, grassi, fibre) oltre ai carboidrati.
3. Integrazione con sistemi di monitoraggio del glucosio per utenti diabetici, con ottimizzazione basata sull'indice glicemico.
4. Interfaccia mobile per consentire l'accesso al sistema da dispositivi mobili, con possibilità di scansione di ingredienti e suggerimenti in tempo reale.
NutriCHOice dimostra come un'architettura ben progettata, combinata con tecniche avanzate di AI e un'attenzione meticolosa ai dettagli di implementazione, possa portare a sistemi che uniscono creatività e precisione scientifica per rispondere a esigenze reali degli utenti.
Risorse e Riferimenti
Repository e Demo
Documentazione Tecnica
- README del progetto: Documentazione dettagliata sull'architettura, installazione e utilizzo
- Model Schema: Definizioni complete dei modelli dati utilizzati
- Workflow Diagram: Diagramma del flusso di lavoro LangGraph
Ringraziamenti
Questo progetto è stato reso possibile grazie al supporto e alla formazione ricevuti da diverse organizzazioni e individui eccezionali:
- Edgemony, per aver organizzato il Bootcamp AI che ha fornito il contesto per lo sviluppo di questo progetto
- Coding Women Sicily, per la loro straordinaria iniziativa volta a promuovere la partecipazione femminile nel mondo tech e per la borsa di studio che mi ha permesso di partecipare a questo percorso formativo trasformativo
- I docenti di Vedrai per la loro competenza, disponibilità e insegnamenti di altissimo livello
- I tutor di Aitho per il loro supporto costante, la pazienza e i preziosi consigli durante tutto il processo di sviluppo
Un ringraziamento particolare va alle mie fantastiche compagne di team, senza le quali questo progetto non sarebbe stato possibile:
NutriCHOice è stato sviluppato come parte del Bootcamp AI di Edgemony dal team "Import Error: Domenico Not Found".